El ToolBox del Data Scientist - Parte I

El ToolBox del Data Scientist - Parte I
Durante mi regreso en el bus que me lleva desde la escuela de mis hijas hasta casa siempre se me ocurren cosas que quiero hacer, ideas relacionadas con un proyecto de DataScience o Machine Learning por ejemplo. Cosas super cool e interesantes, pero siempre me tropiezo con un pequeño problema, pero que no es tan pequeño para cuando DataScience se trata: La disponibilidad de los Datos. Los Datos o Data son el petroleo del futuro y estoy seguro que ser convertirán en el recurso más importante, si es que ya no lo es, para los próximos 50 años.
Es por eso que todo Data Scientist debe contar dentro de su caja de herramienta o ToolBox con herramientas que nos permitan obtener los datos deseados para ese curioso proyecto. No siempre tendremos la facilidad de contar con una API que nos facilite el trabajo.
Ya he hablado anteriormente de Scrapy en el siguiente artículo:
Scrapy es perfecto para WebSites que contienen información presentada usando HTML regular, pero seguramente nos enfrentaremos a fuentes de datos un poco más complicadas, que usen framewoks tales como Angular o React donde la visualización de la página es dinámica. Es alli donde tenemos que utilizar otro tipo de tecnología como es el caso de Selenium .
Selenium es una herramienta que nos permite automatizar acciones en nuestro navegador. Eso es todo! como lo dice su página oficial. Selenium es comunmente usado para dos táreas:
- En el mundo del desarrollo se usa para la automatización de pruebas de UI (Interfaz de Usuario)
- En el mundo del Data Science es usado para WebScraping.
Nuestro viejo amigo Docker
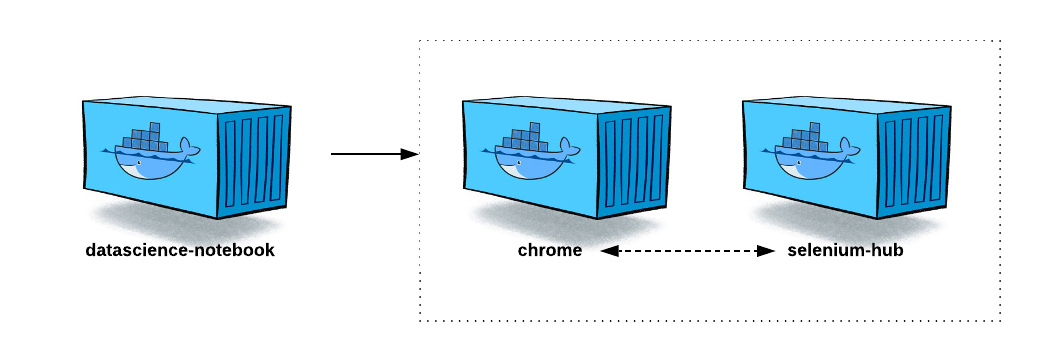
Igualmente en este blog les he hablado acerca de Docker y de algunas imágenes usadas. Hoy quiero compartir con todos Uds. un repositorio Git que pueden clonar donde hay una archivo de Docker-Compose que integra tres containers de Docker para poder usar Selenium desde la comodidad de un Jupyter Notebook. Haciendo uso de tres Cajas:
version: '3'
services:
selenium-hub:
image: selenium/hub:3.141.59-dubnium
ports:
- "4444:4444"
chrome:
image: selenium/node-chrome:3.141.59-dubnium
volumes:
- /dev/shm:/dev/shm
depends_on:
- selenium-hub
environment:
- HUB_HOST=selenium-hub
- HUB_PORT=4444
datascience-notebook:
image: ${IMAGE_NAME}
volumes:
- ${LOCAL_WORKING_DIR}:/home/jovyan/work
- ${LOCAL_DATASETS}:/home/jovyan/work/datasets
- ${LOCAL_MODULES}:/home/jovyan/work/modules
- ${LOCAL_SSL_CERTS}:/etc/ssl/notebook
ports:
- ${PORT}:8888
container_name: jupyter_notebook
command: "start-notebook.sh \
--NotebookApp.password=${ACCESS_TOKEN} \
--NotebookApp.certfile=/etc/ssl/notebook/cert.pem
--NotebookApp.keyfile=/etc/ssl/notebook/privkey.pem"
restart: always
depends_on:
- chrome
En este caso tenemos los siguientes contenedores:
datascience-notebook: que en si mismo es un jupyter notebook server con todas su capacidades. Para su configuración basta con leer el README.mdselenium-hub: El selenium hub nos permite ejecutar diferentes nodes de Selenium, con diferentes drivers y diferentes características.
chrome: es el nodo como tal de selenium que estará encargado de descargar el URL deseado para su procesamiento.
Usando Selenium con Jupyter Notebook
Una ves configurado nuestro Docker Environment, solo necesitamos crear un nuevo Notebook y ejecutar los siguientes comandos:
try:
from selenium import webdriver
except:
!pip install selenium
from bs4 import BeautifulSoup as bs
import time
import re
from urllib.request import urlopen
import json
from pandas.io.json import json_normalize
import pandas as pd, numpy as np
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
cap = DesiredCapabilities.CHROME
driver = webdriver.Remote(command_executor='http://selenium-hub:4444/wd/hub',desired_capabilities=cap)
Suponiendo que quieran descargar la página principal de Python:
driver.get('https://python.org')
Si quieren saber más al respecto de como usar Selenium para WebScraping les recomiendo los siguientes links:
- http://robertorocha.info/setting-up-a-selenium-web-scraper-on-aws-lambda-with-python/
- https://github.com/SeleniumHQ/docker-selenium
- https://towardsdatascience.com/an-introduction-to-web-browser-automation-with-selenium-and-docker-containers-c1bcbcb91540
- https://medium.com/@srujana.rao2/scraping-instagram-with-python-using-selenium-and-beautiful-soup-8b72c186a058
Te ha ayudado esta página? Considera compartirlo 🙌
José Fernando González Montero
Data Scientist / FullStack Python Web Developer
Siempre aprendiendo y queriendo saber más. Me encanta ser parte de proyectos en donde continuo desarrollando mis habilidades.