Web Scraping con Scrapy Framework y Jupyter
Usando Scrapy Framework dentro de Jupyter Notebooks
En el mundo del Data Science y de los proyectos de Web Development es cada vez más común e incluso necesario tener habilidades y conocimiento al menos básicos de Web Scraping.
Scrapy Framework se ha convertido en uno de los frameworks basados en Python más poderoso, versatil y usado para la creación de spiders.
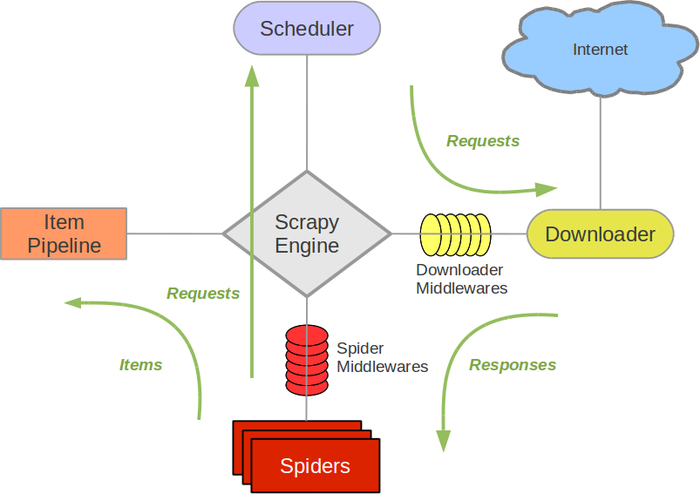
Su arquitectura basada en Pipelines, Schedulers, Spiders y Downloaders permite al desarrollador tener un impresionante control sobre todo el proceso de Scraping.
De igual forma, Jupyter se ha convertido en la herramienta inseparable de todo Data Scientist. Es por eso que les traigo en esta ocasión este Post de comó usar Scrapy dentro de un Jupyter Notebook.
¿Qué necesitamos?
Necesitamos asegurarnos de instalar la libreria. Para ello solo tendremos que ejecutar el siguiente comando dentro de nuestro notebook (puedes saltartelo si estás seguro de que ya la tienes).
!pip install scrapy
Collecting scrapy
Using cached https://files.pythonhosted.org/packages/dd/4f/640343805541c782ee49b14055a85da816cc118a8f48d01b56d2e5d12bf1/Scrapy-1.7.4-py2.py3-none-any.whl
Requirement already satisfied: pyOpenSSL in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from scrapy) (19.0.0)
Collecting queuelib (from scrapy)
Using cached https://files.pythonhosted.org/packages/4c/85/ae64e9145f39dd6d14f8af3fa809a270ef3729f3b90b3c0cf5aa242ab0d4/queuelib-1.5.0-py2.py3-none-any.whl
Requirement already satisfied: six>=1.5.2 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from scrapy) (1.12.0)
Collecting w3lib>=1.17.0 (from scrapy)
Using cached https://files.pythonhosted.org/packages/6a/45/1ba17c50a0bb16bd950c9c2b92ec60d40c8ebda9f3371ae4230c437120b6/w3lib-1.21.0-py2.py3-none-any.whl
Collecting PyDispatcher>=2.0.5 (from scrapy)
Using cached https://files.pythonhosted.org/packages/cd/37/39aca520918ce1935bea9c356bcbb7ed7e52ad4e31bff9b943dfc8e7115b/PyDispatcher-2.0.5.tar.gz
Collecting Twisted>=13.1.0; python_version != "3.4" (from scrapy)
Using cached https://files.pythonhosted.org/packages/61/31/3855dcacd1d3b2e60c0b4ccc8e727b8cd497bd7087d327d81a9f0cbb580c/Twisted-19.7.0.tar.bz2
Collecting service-identity (from scrapy)
Using cached https://files.pythonhosted.org/packages/e9/7c/2195b890023e098f9618d43ebc337d83c8b38d414326685339eb024db2f6/service_identity-18.1.0-py2.py3-none-any.whl
Collecting parsel>=1.5 (from scrapy)
Using cached https://files.pythonhosted.org/packages/86/c8/fc5a2f9376066905dfcca334da2a25842aedfda142c0424722e7c497798b/parsel-1.5.2-py2.py3-none-any.whl
Requirement already satisfied: lxml; python_version != "3.4" in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from scrapy) (4.3.3)
Collecting cssselect>=0.9 (from scrapy)
Using cached https://files.pythonhosted.org/packages/3b/d4/3b5c17f00cce85b9a1e6f91096e1cc8e8ede2e1be8e96b87ce1ed09e92c5/cssselect-1.1.0-py2.py3-none-any.whl
Requirement already satisfied: cryptography>=2.3 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from pyOpenSSL->scrapy) (2.7)
Collecting zope.interface>=4.4.2 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
[?25l Downloading https://files.pythonhosted.org/packages/d9/3a/101934e0f2026f0a58698978bfedec6e2021b28b846d9e1d9b54369e044d/zope.interface-4.6.0-cp37-cp37m-macosx_10_14_x86_64.whl (131kB)
[K |████████████████████████████████| 133kB 4.2MB/s eta 0:00:01
[?25hCollecting constantly>=15.1 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
Using cached https://files.pythonhosted.org/packages/b9/65/48c1909d0c0aeae6c10213340ce682db01b48ea900a7d9fce7a7910ff318/constantly-15.1.0-py2.py3-none-any.whl
Collecting incremental>=16.10.1 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
Using cached https://files.pythonhosted.org/packages/f5/1d/c98a587dc06e107115cf4a58b49de20b19222c83d75335a192052af4c4b7/incremental-17.5.0-py2.py3-none-any.whl
Collecting Automat>=0.3.0 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
Using cached https://files.pythonhosted.org/packages/e5/11/756922e977bb296a79ccf38e8d45cafee446733157d59bcd751d3aee57f5/Automat-0.8.0-py2.py3-none-any.whl
Collecting hyperlink>=17.1.1 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
Using cached https://files.pythonhosted.org/packages/7f/91/e916ca10a2de1cb7101a9b24da546fb90ee14629e23160086cf3361c4fb8/hyperlink-19.0.0-py2.py3-none-any.whl
Collecting PyHamcrest>=1.9.0 (from Twisted>=13.1.0; python_version != "3.4"->scrapy)
Using cached https://files.pythonhosted.org/packages/9a/d5/d37fd731b7d0e91afcc84577edeccf4638b4f9b82f5ffe2f8b62e2ddc609/PyHamcrest-1.9.0-py2.py3-none-any.whl
Requirement already satisfied: attrs>=17.4.0 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from Twisted>=13.1.0; python_version != "3.4"->scrapy) (19.1.0)
Requirement already satisfied: pyasn1 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from service-identity->scrapy) (0.4.5)
Requirement already satisfied: pyasn1-modules in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from service-identity->scrapy) (0.2.5)
Requirement already satisfied: asn1crypto>=0.21.0 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from cryptography>=2.3->pyOpenSSL->scrapy) (0.24.0)
Requirement already satisfied: cffi!=1.11.3,>=1.8 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from cryptography>=2.3->pyOpenSSL->scrapy) (1.12.3)
Requirement already satisfied: setuptools in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from zope.interface>=4.4.2->Twisted>=13.1.0; python_version != "3.4"->scrapy) (41.0.1)
Requirement already satisfied: idna>=2.5 in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from hyperlink>=17.1.1->Twisted>=13.1.0; python_version != "3.4"->scrapy) (2.8)
Requirement already satisfied: pycparser in /Users/jfgonzalezm/anaconda3/lib/python3.7/site-packages (from cffi!=1.11.3,>=1.8->cryptography>=2.3->pyOpenSSL->scrapy) (2.19)
Building wheels for collected packages: PyDispatcher, Twisted
Building wheel for PyDispatcher (setup.py) ... [?25ldone
[?25h Stored in directory: /Users/jfgonzalezm/Library/Caches/pip/wheels/88/99/96/cfef6665f9cb1522ee6757ae5955feedf2fe25f1737f91fa7f
Building wheel for Twisted (setup.py) ... [?25ldone
[?25h Stored in directory: /Users/jfgonzalezm/Library/Caches/pip/wheels/f4/2b/d5/bf550d6bead12fec7a1383be4e994758848c4aeeb9fc627ecf
Successfully built PyDispatcher Twisted
Installing collected packages: queuelib, w3lib, PyDispatcher, zope.interface, constantly, incremental, Automat, hyperlink, PyHamcrest, Twisted, service-identity, cssselect, parsel, scrapy
Successfully installed Automat-0.8.0 PyDispatcher-2.0.5 PyHamcrest-1.9.0 Twisted-19.7.0 constantly-15.1.0 cssselect-1.1.0 hyperlink-19.0.0 incremental-17.5.0 parsel-1.5.2 queuelib-1.5.0 scrapy-1.7.4 service-identity-18.1.0 w3lib-1.21.0 zope.interface-4.6.0
[33mWARNING: You are using pip version 19.1.1, however version 19.3.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.[0m
Verás finalmente la confirmación de que ha sido instalada. Ahora debemos importar las siguientes librerias:
import scrapy
from scrapy.crawler import CrawlerProcess
Estamos listos para crear un Pipeline. Los pipelines son uno de los componentes principales del Scrapy Framework. En este ejemplo JsonWriterPipeline es una clase que se encargará de convertir todos los elementos conseguidos a un archivo JSON donde cada linea es un elemento.
import json
class JsonWriterPipeline(object):
def open_spider(self, spider):
self.file = open('resultados.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
Luego, necesitamos definir la Spider como tal. La scrapy.Spider es una clase donde se define el comportamiento de nuestra spider.
import logging
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
custom_settings = {
'LOG_LEVEL': logging.WARNING,
'ITEM_PIPELINES': {'__main__.JsonWriterPipeline': 1}, # Used for pipeline 1
'FEED_FORMAT':'json', # Used for pipeline 2
'FEED_URI': 'quoteresult.json' # Used for pipeline 2
}
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('span small::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
}
start_urls es una lista de urls donde se puede especificar la dirección web a ser analizada.
custom_settings es un override de los parametros que Scrapy usa por defecto.
Ahora podemos ejecutar nuestra araña.
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
})
process.crawl(QuotesSpider)
process.start()
2019-10-28 22:35:22 [scrapy.utils.log] INFO: Scrapy 1.7.4 started (bot: scrapybot)
2019-10-28 22:35:22 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 05:52:31) - [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Darwin-19.0.0-x86_64-i386-64bit
2019-10-28 22:35:22 [scrapy.crawler] INFO: Overridden settings: {'FEED_FORMAT': 'json', 'FEED_URI': 'quoteresult.json', 'LOG_LEVEL': 30, 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'}
Como lo hemos especificado en la clases, el archivo resultados.jl va a contener el resultado del scraping. Veamos que contiene:
!cat resultados.jl
{"text": "\u201cThis life is what you make it. No matter what, you're going to mess up sometimes, it's a universal truth. But the good part is you get to decide how you're going to mess it up. Girls will be your friends - they'll act like it anyway. But just remember, some come, some go. The ones that stay with you through everything - they're your true best friends. Don't let go of them. Also remember, sisters make the best friends in the world. As for lovers, well, they'll come and go too. And baby, I hate to say it, most of them - actually pretty much all of them are going to break your heart, but you can't give up because if you give up, you'll never find your soulmate. You'll never find that half who makes you whole and that goes for everything. Just because you fail once, doesn't mean you're gonna fail at everything. Keep trying, hold on, and always, always, always believe in yourself, because if you don't, then who will, sweetie? So keep your head high, keep your chin up, and most importantly, keep smiling, because life's a beautiful thing and there's so much to smile about.\u201d", "author": "Marilyn Monroe", "tags": ["friends", "heartbreak", "inspirational", "life", "love", "sisters"]}
{"text": "\u201cIt takes a great deal of bravery to stand up to our enemies, but just as much to stand up to our friends.\u201d", "author": "J.K. Rowling", "tags": ["courage", "friends"]}
{"text": "\u201cIf you can't explain it to a six year old, you don't understand it yourself.\u201d", "author": "Albert Einstein", "tags": ["simplicity", "understand"]}
{"text": "\u201cYou may not be her first, her last, or her only. She loved before she may love again. But if she loves you now, what else matters? She's not perfect\u2014you aren't either, and the two of you may never be perfect together but if she can make you laugh, cause you to think twice, and admit to being human and making mistakes, hold onto her and give her the most you can. She may not be thinking about you every second of the day, but she will give you a part of her that she knows you can break\u2014her heart. So don't hurt her, don't change her, don't analyze and don't expect more than she can give. Smile when she makes you happy, let her know when she makes you mad, and miss her when she's not there.\u201d", "author": "Bob Marley", "tags": ["love"]}
{"text": "\u201cI like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.\u201d", "author": "Dr. Seuss", "tags": ["fantasy"]}
{"text": "\u201cI may not have gone where I intended to go, but I think I have ended up where I needed to be.\u201d", "author": "Douglas Adams", "tags": ["life", "navigation"]}
{"text": "\u201cThe opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.\u201d", "author": "Elie Wiesel", "tags": ["activism", "apathy", "hate", "indifference", "inspirational", "love", "opposite", "philosophy"]}
{"text": "\u201cIt is not a lack of love, but a lack of friendship that makes unhappy marriages.\u201d", "author": "Friedrich Nietzsche", "tags": ["friendship", "lack-of-friendship", "lack-of-love", "love", "marriage", "unhappy-marriage"]}
{"text": "\u201cGood friends, good books, and a sleepy conscience: this is the ideal life.\u201d", "author": "Mark Twain", "tags": ["books", "contentment", "friends", "friendship", "life"]}
{"text": "\u201cLife is what happens to us while we are making other plans.\u201d", "author": "Allen Saunders", "tags": ["fate", "life", "misattributed-john-lennon", "planning", "plans"]}
{"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d", "author": "Albert Einstein", "tags": ["change", "deep-thoughts", "thinking", "world"]}
{"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d", "author": "J.K. Rowling", "tags": ["abilities", "choices"]}
{"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d", "author": "Albert Einstein", "tags": ["inspirational", "life", "live", "miracle", "miracles"]}
{"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d", "author": "Jane Austen", "tags": ["aliteracy", "books", "classic", "humor"]}
{"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d", "author": "Marilyn Monroe", "tags": ["be-yourself", "inspirational"]}
{"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d", "author": "Albert Einstein", "tags": ["adulthood", "success", "value"]}
{"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d", "author": "Andr\u00e9 Gide", "tags": ["life", "love"]}
{"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d", "author": "Thomas A. Edison", "tags": ["edison", "failure", "inspirational", "paraphrased"]}
{"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d", "author": "Eleanor Roosevelt", "tags": ["misattributed-eleanor-roosevelt"]}
{"text": "\u201cA day without sunshine is like, you know, night.\u201d", "author": "Steve Martin", "tags": ["humor", "obvious", "simile"]}
Pues alli lo tienen. Espero que les sea de mucha utilidad. Si tienen alguna duda, les recomiendo ampliamente el Tutorial en la documentación oficial de Scrapy.
Para la elaboración del este POST, me he inspirado en el siguiente enlace: https://www.jitsejan.com/using-scrapy-in-jupyter-notebook.html
Te ha ayudado esta página? Considera compartirlo 🙌
José Fernando González Montero
Data Scientist / FullStack Python Web Developer
Siempre aprendiendo y queriendo saber más. Me encanta ser parte de proyectos en donde continuo desarrollando mis habilidades.